@来雨轩等:《基于大语言模型与检索增强的学科试题生成方法》
总结📔
研究方法就是提示词+RAG,似乎没啥新的,似乎在应用层的产品已经有很多了。(注意对于大模型生成结果格式不对的情况,本文采用了重新提问的方式)
写成论文就要注意:方法的评估,即证明这个方法是有效的,一般思路就是找基线模型对比,然后人工评估+自动评估。并且要定量+定性(对错多少,对错在哪里并举例)
分析部分延伸探讨了一些小问题,也是可扩展的方向。
摘要
- 研究背景:智能命题是自然语言处理与智能教育的交叉领域的重要任务。
- 现有问题:现有方法过于关注材料文本细节,忽略对知识点本身的考察。
- 研究方法:提出一种基于大语言模型与检索增强技术的学科试题生成方法。
- 设计明确的指令提问方式。
- 融合少样本语境学习与检索得到的教材相关信息。
- 激发大语言模型的潜力,使生成试题在风格和难度上符合实用需求。
- 研究结果:
- 在自动评价和人工评价中,本文方法较基线模型取得了更高的可用率和多样性。
- 直接可用率达到人类专家的 77.5%,且高质量试题的比例略超过人工结果。
- 关键词:大语言模型;检索增强技术;问题生成;智慧教育
1. 引言
- 背景:智能命题利用人工智能技术,基于样例试题、教材内容和知识点,自动生成考试题目。
- 意义:人工智能在现代教育领域的重要应用之一。
- 需求:教师编制新试题耗时,线上及翻转课堂教学模式增加对高质量试题的需求。
- 问题:现有问题生成研究集中于语言学习和场景理解,测试从文本中提取事实知识的能力,忽略了对知识点本身的考察,不适合试题编制。
- 研究范围:专注于生成选择题与判断题。
- 实验:以“Python 语言基础”高等教育课程为例。
- 结果:自动评估和人工评估结果表明,本文提出的命题方法在试题可用性等指标上优于基线方法。
- 贡献:
- 提出了一种基于大语言模型和检索增强的学科试题生成方法,通过融合教材检索信息和少样本语境学习,有效提升大语言模型在试题生成上的表现。
- 在基于样卷的题库构建场景下,设计并实现了基于生成型大模型和检索增强的试题生成方法。
- 通过对两种题型生成的实验,发现本文方法在自动评价指标和人工评价中均显示出良好的效果和应用潜力。
2. 相关工作
2.1 问题生成
- 定义:根据一定的文本上下文和可选答案生成事实性问题。
- 现有问题:过度侧重对文本内容的理解,可能不完全适合学科教育类试题的生成任务。
- 本文策略:采用基于大型语言模型的端到端问题生成策略,并设计针对试题命制特性和检索增强需求的有效提词策略,进一步挖掘大语言模型在试题生成方面的潜力。
2.2 大语言模型赋能教育
- 应用:大语言模型答疑与教学助理,解答中学历史学科问题,在编程教学场景下对学生给出引导与反馈,或作为教学者的生产力辅助工具。
- 现有研究:使用 GPT-3 和 ChatGPT,基于零监督的题词法生成指定难度的中小学数学题;利用精细设计的提词法和 ChatGPT 生成选择题以检查英语词汇水平;使用简单的指令结合少监督 Prompt 生成指定难度和考察认知层次的问题。
- 本文不同之处:针对学科试题着重考察知识掌握情况的特点,基于样卷以知识点为单位展开命题,并精细设计了结合少样本上下文学习与检索增强技术的提问方式,更有效地发掘了大模型的能力以满足任务需求。
3. 本文方法
3.1 任务定义
- 目标:基于样卷的学科试题库构建。
- 输入:课程教材 T,样卷 Q = {qi},每个问题 qi 包括题干、答案、选项、题型 ti 和知识点 ki。(ci 可选,为教材文本信息)
- 输出:试题库 Q'。
- 方法:基于知识点的端到端问题生成框架。
- 公式:<Q'i> = LLM({qj}, ti, ki, ci)
3.2 方法框架
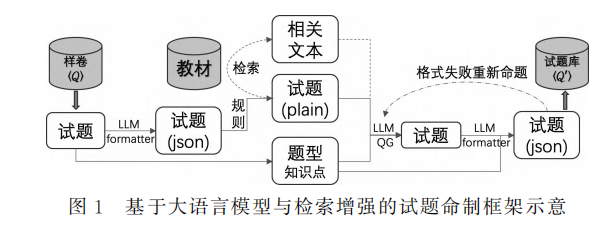
- 流程:
- 从样卷 Q 中选取的试题,通过基于大语言模型的格式解析器 (LLMformatter) 转换成 json 格式,再通过规则扁平化为文本形式 (试题 plain)。
- 扁平化后的试题与题型、知识点等信息一同被输入到基于大模型的问题生成器中 (LLMQG)。
- 对于检索增强部分,则利用扁平化后的试题表述检索教材中的相关文本,并将检索到的文本结合到问题生成中。
- 生成后的试题会再通过一次格式解析器转化成 json 格式。
- 在转化过程中出错的试题,会被退回并让大语言模型重新命制。
- 解析成功的试题会收入构建的试题库 Q' 中。
3.3 基于大模型的格式解析器
- Prompt-1: 用于将问题调整为 json 格式
请参照如下样例, 调整给出的问题为 json 格式: raw-prompt 样例输入: ex_in 样例输出: ex_out 待处理输入: q_in 你需要处理上述 n 道题, 每道题处理结果为 1 行 json, 一共输出 n 行。 - Prompt-2: 用于修正json格式错误
不好意思, 之前输出的 json 格式不对, 请确保输出内容为 n 行, 并且每行为一个 json 格式的字符串。可以参照样例输入。 raw_prompt - 作用:格式转化,对问题生成结果做格式检查,实现大模型的自我反省。
3.4 教材检索
- 目的:权衡问题多样性与同知识点之间的相关性。
- 步骤:
- 教材文本清洗与内容分块:去除图片、注释、前言、附录、书后习题等内容,按照“章-节-小节”的三级标题分割教材,再对较长的小节以段落为单位按长度分块,每块长度不超过 600 字符,且块与块之间重叠不超过 180 字符。
- 利用段落嵌入构建索引:采用 OpenAI 的 text-embedding-ada-002 模型。
- 检索查询:采用基于余弦相似度的方式,利用 Python 的 ChromaDB 工具构建索引并完成查询。
3.5 问题生成提问设计
- Prompt-3: 基于少样本学习与检索增强的问题生成提问方式
请先阅读以下 Python 语言基础课程教材中的文本片段: bookinfo 接下来, 我向你展示 n_1 道和这个文本片段相关的 q_type: q_in 接下来, 你需要仿照这些试题的出法, 依据给定教材中的内容, 帮我出 n_2 道 q_type。这些题关注的知识点为: keywords。你新出的 q_type 将用于计算机学科 Python 语言基础课程的期末考试。你的输出应该为 n2 行, 每行为 1 道题 - Prompt-4: 用于格式错误时重新生成
不好意思, 之前输出的格式不对, 请确保输出内容为 n2 行, 并且每行对应一道题。可以参照样例。 raw_prompt - Prompt-5: 不使用检索增强生成
请参照下面 n1 道 qtype: 参考题: q_in 接下来, 你需要仿照这些试题的出法, 依据给定教材中的内容, 帮我出 n2 道 qtype。这些题关注的知识点为: keywords。你新出的 qtype 将用于计算机学科 Python 语言基础课程的期末考试。你的输出应该为 n2 行, 每行为 1 道题。
4. 实验
4.1 实验设置
- 问题生成模型: OpenAI 的 GPT-4-1106-preview 版本。
- 格式解析器模型: GPT-3.5-turbo-0613。
- 课程:“Python 语言基础”。
- 样卷:30 道试题,其中单选题和判断题各 15 题,每道题均标注了所属知识点。
- 策略:one-shot 上下文学习,选用相同知识点且相同题型的样例作为上下文学习的提示样例。
- 规模:要求每种方法为每个样例问题生成 4 个同知识点问题,即要基于样卷构建 120 道题目规模的题库。
- 教材:“Python 语言基础”教材,正文部分总共有 15.4 万个字符,132 个小节,分为 369 个检索块。
- 检索增强:使用检索得到的相关度最高的 1 个内容块。
4.2 基于大语言模型的基线模型
- 基线模型: Elkins 等人提出的结合上下文的少监督提词法,生成中等难度试题的提词法 (Prompt-6)。
生成中等难度的试题. 注意一次需要生成 n2 道试题。不要忘记输出答案. 文档:{bookinfo} 问题:{q_in} 问题: - 改进:
- 将该基线方法的基座模型从 text-davinci-003 替换为 GPT-4-1106-preview。
4.3 生成问题的可用性
- 方法:人工打分评价。
- 流程:将基线模型、本文提词法 (Prompt-5)、本文结合检索增强生成的方法 (本文提词法+RAG, Promp-3) 构建的题库,以及样题混合,共 390 道题目,让标注者进行标注。
- 标注者:在该课程任教多年并且熟悉教材的高校教师。
- 标注指令:“您正在参与一项人工智能辅助命题的实验。我会给您一些试题,您需要标注哪些题目可以用于 Python 语言基础课程期末考试。不可以直接使用的直接删去。对于经过简单修改就可使用的试题,请记录题目编号及修改方式。同时,请记录一批优质试题的编号。这些题目将在下一轮人工智能命题中作为种子样例。”
- 结果:本文提出的基于大语言模型和检索增强技术的试题命制方法的不可用率最低、好题率最高,体现了本文方法的有效性。
- 本文
提词法+RAG方法直接可用率+好题率达到 77.5%,平均每个知识点不可用的试题数少于 1 题。- 总好题率达到 24.2%,甚至超过了混在其中的样题的好题率,这表明本文方法可以有效地在样题的基础上扩充可用的试题以构建试题库,并且试题质量可以达到甚至部分超过人类水平。
- 对比本文
提词法+RAG与不包含检索增强的本文提词法生成结果可以发现,本文提词法+RAG 可以带来明显的好题率的提升 (+8.4%),总可用率也略有提高 (+1.7%)。 - 对比本文
提词法+RAG与基线模型的生成结果,可以发现本文提词法+RAG 生成的题目无论是可用率还是好题率都有明显的提升。 - 从题型看,
单选题不同的方法生成结果的可用性评分区分度较大,而判断题的可用性评分区分度不高,好题率整体偏低。(因为判断题发挥空间不大)
- 本文
4.4 对比经典问题生成方法
- 基线:
- lmqg: 基于多语言 T5 模型与中文问答数据集精调的问题生成模型
- seq2seq BART: 基于 BART 模型, 输入基于本文 2.5 节设计的 prompt-5, 但受限于 BART 的上下文长度, 去掉了提示语中的展示样本。
- 结果: lmqg 和 seq2seq BART 生成问题的可用率分别为 5% 和 0%。(过度关注文本细节,或格式不完整)
- 结论: 经典问题方法难以同时满足学科试题生成任务要求的少样本监督、复杂问题格式 (包含问题 + 答案 + 候选项等)、知识点考察这三大核心需求。
4.5 案例研究
- 结论:本文设计的提词法的有效性。
- 结果:
- 没有使用检索增强的方法 (本文提词法) 生成的试题同样题相似度较高。
- 在结合检索增强的生成方法 (本文提词法+RAG) 中,大语言模型可以利用检索到的教材信息扩展生成问题的内容,从而在参照样题的同时更全面地考察知识点。
4.6 分析
- 问题1: 可用性评价的信度如何?
- 方法: Kappa系数
- 结果: Kappa系数为 0.73, 提示显著一致 (substantial agreement)。表明可用性评价具有较高的信度。
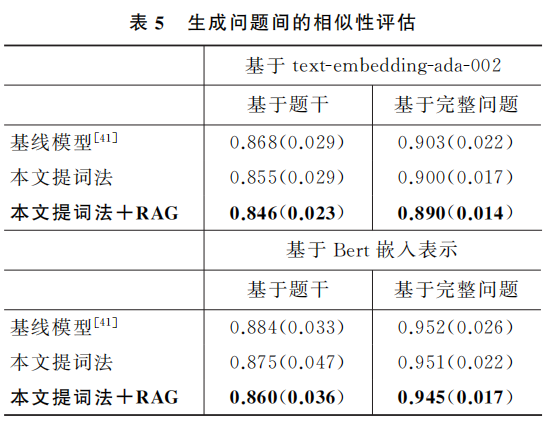
- 问题2: 结合检索增强方法是否可以提升生成问题的多样性?
- 方法: 计算问题嵌入表示的余弦相似度
- 结果: 本文结合检索增强的方法生成试题间的相似度是最低的, 说明了多样性更好。
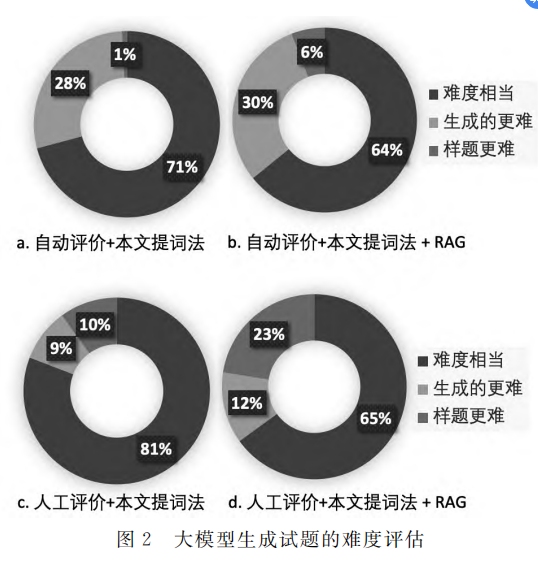
- 问题3: 使用生成式大模型生成的试题难度如何?
- 方法: 人工评价和自动评价 (GPT-4-1106-preview 模型)
- 结果: 大模型生成的试题大多都和样题难度差别不大, 人工评价和自动评价的结果表明有 64%~81% 的生成题目难度与样题相当。
- 问题4: 结合大模型与检索增强的试题命制方法会生成怎样的不可用试题?
- 原因分析:
- 考查内容过于针对教材文本细节 (38%)
- 考察的知识点太简单或没有意义 (27%)
- 考察了使用频率较低的编程方法细节 (23%)
- 忽视了极端情况导致答案不正确 (8%)
- 考察内容不明确, 看不懂 (4%)
- 原因分析:
5. 总结与展望
- 本文工作:
- 提出了一种基于大语言模型与检索增强的问题生成方法,结合少监督语境学习与检索增强技术,设计了一种指令提词法以激发大语言模型的相关能力。
- 在 Python 语言基础课程客观题命制场景下,该方法能够基于一套样卷扩充生成题库。
- 对两种题型的人工测评与自动测评结果表明,本文提出的方法生成的问题在可用性、多样性等方面较基线模型有所提升,在问题难度方面与样题相当。
- 生成的问题可用性接近人类专家水平,具有潜在的应用价值。
- 开展了错误分析,归纳整理生成的不可用的问题原因,为未来的工作提供潜在方向。
- 未来工作:
- 探索在更多的学科上的应用。
- 尝试将生成的问题与自适应学习等技术结合,或用于教学来收集学生反馈,从而带来更高的应用价值与社会效益。